C++
C++ objects, containers and maps
ContentsIn earlier C++ courses you've been introduced to one new idea after another. The aim of this document is generalise and factorise what you already know. The only major concepts we'll introduce will make your programs shorter, safer and faster. They're concepts also adopted by many languages other than C++.
- Objects - a way to make parts of the program more self-contained, tying together data and behaviour. Objects can be related to other objects
- Containers - ways of clumping together variables of the same type so that sorting, searching, etc., becomes easy
- Maps - ways of setting up a mapping between 2 sets of values.
The approach is a little like maths where you try to put the question into a standard canonical form so that you can use standard solution methods. There will be quite a few details to worry about. Fortunately some reasonable online resources exist, and the details are as standardised as possible. As with earlier courses, you'll only see the point of some of these working practises when you write bigger programs. By the end of this document you'll still be writing little programs, but they'd have taken you dozens of lines to write before.
This document contains dozens of exercises, several of which require only minor modifications of the supplied code. The Utilities section has some routines (for timing, random numbers and converting) that you'll need to complete the exercises.
Some C++ will be assumed. Useful local reading includes
- CUED Tutorial Guide to C++ Programming
- 1A C++ coursework, Michaelmas
- 1A C++ coursework, Lent
- 1A CUED C++ crib
- 1B C++ coursework
Classes and Objects (revision) [ back to contents]
In the Michaelmas term we used several types of variables that are always available in C++ - int (for integers), float (for "floating point" numbers), etc. We also used some types that are standard "add-ons" - for example, with
#include <string> using namespace std;
at the top of the file you can use string (for text).
In the Lent term we went further, inventing our own types. We supplied you with a ModelData type, designed to hold all the information about the data. It was created using
class ModelData {
public:
int numPoints;
float x[MAXSIZE];
float y[MAXSIZE];
float a;
float b;
float residual[MAXSIZE];
float mean;
float variance;
float maximum;
float minimum;
};
The line
ModelData data;
creates a variable called data of type ModelData analogously to how
int i;
creates an integer called i, but the entities are more sophisticated now. ModelData is said to be a Class and data is an Object of that class. Matlab, Octave, Java, Python and most other languages nowadays use the same jargon. The components inside the class are called members. The members of an object are accessed and assigned values by specifying the member name and using the dot operator. For example:
data.a = 1.0;
assigns 1.0 to the a variable inside data. This way of bundling together related variables into a bigger variable helps to make the code more organised.
The members in this situation were data of various types. We're now going to put functions as well as data into the objects. This is all part of working in a more object oriented way, which is good for your CV. Before writing our own member functions though, we'll get used to some that already exist in the C++ standard library.
Strings [ back to contents]
Strings are sequences of characters. strings are more sophisticated than simple data like ints and floats. They have extra functionality associated with them. For example, if you want to find the length of a string s, you can use s.size(). Here size is a member function of s. It makes sense to have this function as part of the string class rather than separate because it can only be used with strings. Other member functions exist - for example find (to see if a character's in a string) and erase (to delete characters).
Whenever you deal with objects it's useful to find out what member functions it has. Knowing how to get such information is important - buy a book or look at pages like cplusplus's string page. You might not understand all the features at first, but eventually they'll save you a lot of time "re-inventing the wheel". For example, suppose you wanted to put a * in the centre of a string. You could write the code to do this, shifting the letters that are beyond the half-way point, but you don't need to. Here's the code - it uses 2 member functions.
#include <iostream>
#include <string>
using namespace std;
int main() {
string s = "a long string";
s.insert(s.size()/2,"*");
cout << s << endl;
}
Containers [ back to contents]
 In earlier courses you met arrays. An array contains several variables of the same type. For example,
In earlier courses you met arrays. An array contains several variables of the same type. For example,
int numbers[7];
creates an array called numbers big enough to contain 7 integers, namely numbers[0] ... numbers[6]. Arrays are rather limited - you can't for example change their size once they've been created. C++ has a more sophisticated way of putting together variables of the same type - you can put the variables into containers. The available containers include vector (which is a straight replacement for arrays), list, set, queue etc. All these containers behave as similarly as possible - for example they all have a size() member function, like strings have. In fact, strings behave much like containers, so if you know how to use strings you can use list and vector too - they also have find and erase functions.
Before we can use containers, some notation needs to be introduced
Creating containers
When you create a container, you need to specify what type of container it is and what type of elements it will contain. Optionally you can also give it an inital size. To create a vector called numbers big enough for 7 integers, you need to use
vector<int> numbers(7);
You can also initialise it with values from an array, though you need to get the notation right. For example, the following creates a vector of size 10 using the values in numbersarray.
#include <vector>
using namespace std;
int numbersarray[]={1, 4 , 4 , 7 , 8 , 6 , 8 , 9, 9, 4};
int main () {
vector<int> numbers(numbersarray, numbersarray+10);
}
The angled brackets look a bit unfriendly but you'll get used to them. Once you've created numbers in this way you could use it in just the same way that you used the array, but there's a lot more that you can do too.
Extending a container
The push_back() function lets you lengthen a container by pushing an element onto the back of it. E.g. after
vector<int> v; // creates an empty vector v.push_back(3); v.push_back(8);
v will have 2 elements.
Accessing elements of a container
Once you've created a vector like v you can access the elements in the same way that you accessed array elements. For example,
v[1]=3; v[2]=5; v[3]=v[1]+v[2];
would set v[3] to 8. However, many of the facilities we'll use later need to be given iterators. An iterator is another way to refer to a particular element - it "points to" the element. If it is an iterator, then *it is the value of the element it points to. The begin() member function of any container will return an iterator pointing to the first element, and end() will return an iterator to one beyond the final element (which is often what's required). Future examples will show how to create iterators if you need them - the type of the iterator needs to match the container and its elements. The code for this uses :: (the 'binary scope resolution operator') which you may not have met before. It's used when you want to pick out a member of a class (rather than a member of an object).
Algorithms [ back to contents]
The reason that the different containers were designed to be as similar as possible is so that some standard functions (called Algorithms) can then be provided that will work whatever the type of container it's given. Time for a demo.
There's an algorithm called reverse(). Here's how you use it to reverse a string.
#include <iostream>
#include <algorithm>
#include <string>
using namespace std;
int main() {
string s = "a long string";
// now reverse the whole string from the beginning to the end
reverse(s.begin(), s.end());
cout << s << endl;
}
and here's how you reverse a vector
#include <iostream>
#include <algorithm>
#include <vector>
using namespace std;
int main() {
vector<int> s(3);
s[0]=1; s[1]=2; s[2]=3;
reverse(s.begin(), s.end());
cout << s[0] << s[1] << s[2] << endl;
}
Note that the vector and string are created and printed out differently, but the reverse line is exactly the same. There are about 40 algorithms and 10 types of containers. Each container can have elements that are ints or any other type - even those you've invented yourself (with some restrictions). That's many possible combinations, but because of the design of C++ you don't have to remember much - whether you're reversing a vector of integers or a string of characters, the basic code is the same.
Using algorithms means you need to write fewer for and while loops - a good thing because they're error-prone (as you may already have discovered). Here are a few algorithms with fragments or whole programs to demonstrate their use
- find - looks for a value
vector<int> v; // the next line creates 'it'. Its type is vector<int>::iterator // which is verbose, but logical - it's an iterator for dealing with vector<int> // Not that :: is used because the thing before it is a class, not an object. vector<int>::iterator it; ... it = find (v.begin(), v.end(), 30); if (it == v.end()) cout << "30 not found " << endl; else cout << "30 is in v " << endl; - count - finds how many elements match a given value
vector<int> v; ... cout << "30 is in v " << count(v.begin(), v.end(), 30) << " times" << endl;
- count_if - finds how many elements match a given condition
// full program #include <iostream> #include <vector> #include <algorithm> using namespace std; // The next function returns true if n is a multiple of 3 - // the % operator calculates the remainder after division bool multipleOf3(int n) { return not (n%3); } int main() { vector<int> v(10); for (int i=0;i<v.size();i++) v[i]=i; cout << count_if(v.begin(), v.end(),multipleOf3) << " multiples" << endl; } - for_each - like a "for" loop, but can't change the container's values
void square(int n) { cout << n*n << endl; } int main() { vector<int> v; ... // print the square of all the values in v for_each(v.begin(), v.end(), square); } - transform - like a "for" loop; you can change the container's values
int square(int n) { return n*n; } int main() { vector<int> v; ... // replace each value in v by its square transform(v.begin(), v.end(), square); } - replace - replaces values
vector<int> v; ... // replace 7s by 3s replace(v.begin(), v.end(), 7,3); - fill - fills a container with a value
vector<int> v; fill(v,9); - copy - copies a container, or part of it. The following code copies a vector to a list
// full program #include <vector> #include <list> #include <algorithm> using namespace std; int main() { vector<int> v(10); for (int i=0;i<v.size();i++) v[i]=i; list<int> l(10); copy(v.begin(), v.end(),l.begin()); } - remove - removes all the items with a particular value (actually it moves all those items to the end of the vector - you can delete them later if you wish)
vector<int> v; vector<int>::iterator it; it=remove (v.begin(), v.end(), 7);
- unique - puts duplicates at the end of the vector (but copies need to be contiguous with originals). You can delete the duplicates afterwards.
// full program #include <iostream> #include <algorithm> #include <string> using namespace std; int main () { string s="holly root"; string::iterator it; cout << "s original: " << s<<endl; it=unique(s.begin(),s.end()); // 'it' points to the 1st of the duplicates cout << "s after unique:" << s<<endl; s.erase(it, s.end()); cout << "s after erase: " << s<<endl; } - unique_copy - copies the unique elements to a new place (but copies need to be contiguous with originals).
// full program #include <iostream> #include <algorithm> #include <string> using namespace std; int main () { string s="holly root"; string t=" "; cout << "s original: " << s<<endl; // copy the unique characters from string s to string t (but t needs to be // big enough to contain the characters) unique_copy(s.begin(),s.end(),t.begin()); cout << "s after: " << s<<endl; cout << "t after: " << t<<endl; } - set_intersection - intersection of 2 sorted containers
// full program #include <iostream> #include <vector> #include <algorithm> using namespace std; int main () { vector<int> set1(3); vector<int> set2(3); vector<int> answer(3); set1[0]=1; set1[1]=2; set1[0]=3; set2[0]=2; set2[1]=4; set2[0]=6; vector<int>::iterator it; // the next line puts the common values into the 'answer' vector // returning a pointer to the element just beyond answer's last element it=set_intersection (set1.begin(), set1.end(),set2.begin(), set2.end(), answer.begin()); cout << "Number of common values=" << answer.size() << endl; - min_element - finds the minimum
vector<int> v; vector<int>::iterator it; it=min_element(v.begin(), v.end()); cout << *it << endl;
- next_permutation - finds the next permutation
// full program #include <iostream> #include <algorithm> using namespace std; int main () { vector<int> myints(3); myints[0]=1; myints[1]=2; myints[2]=3; sort (v.begin(),v.end()); // only really needed if the elements are unsorted cout << "The 3! possible permutations with 3 elements:\n"; do { cout << myints[0] << " " << myints[1] << " " << myints[2] << endl; } while ( next_permutation (v.begin(),v.end()) ); } - accumulate - adds the elements (needs #include <numeric>)
- partial_sum - replaces each element by successive partial sums (needs #include <numeric>)
// full program #include <iostream> #include <algorithm> #include <numeric> using namespace std; int main () { // create a vector big enough to hold 10 ints vector<int> v(10); // fill it with 1s fill(v.begin(), v.end(), 1); // work out partial sums and put the answer back in v partial_sum(v.begin(), v.end(),v.begin() ); // v now contains 1....10. Now sum the elements using 0 as the initial sum cout << "Sum of elements=" << accumulate(v.begin(), v.end(),0) << endl; }
Many of these algorithms can take extra options (e.g. so that the output can go in a new container). Often you won't know how big to make the new container. Fortunately there's a feature that lets you add output to a container so that the container expands if necessary - you use back_inserter to insert new items onto the back of a container. Here's an example
#include <iostream>
#include <algorithm>
#include <string>
using namespace std;
int main () {
string s="holly root";
string t;
cout << "s original: " << s<<endl;
unique_copy(s.begin(),s.end(),back_inserter(t));
cout << "s after: " << s<<endl;
cout << "t after: " << t<<endl;
}
Algorithm Exercises [ back to contents]
Except for the last 4, none of these programs should be longer than 10 lines, and mostly they're variations of the examples shown earlier. For some of the later exercises you'll find the routines in the Utilities section useful.
- Write a program that creates a string then puts the characters in alphabetical order (there's a sort algorithm).
- Write a program that creates a string then shuffles the characters (there's a random_shuffle algorithm)
- Write a program that creates a vector of strings and then puts the strings in alphabetical order
- Write a program that creates 2 strings then prints out the letters they have in common.
- Write a program that creates a string then removes the spaces in the string (use remove and erase).
- Write a program that creates a string then counts the number of times that a particular letter ('t' for example) appears in the string. (there's a count algorithm).
- Write a function that given 2 strings tells you if one is a palindrome of the other (use reverse on one string and see if it matches the other)
- Write a program that creates a vector of floats and reverses them.
- Complete the for_each example to create a program that prints the squares of integers from 1 to 10
- Adapt the previous program so that the squares are summed (use transform and accumulate)
- Make the previous program into a function that given an integer n returns the sum of the squares from 1 to n
- Here's a program that creates a vector v then copies all the
multiples of 2 that it contains into a vector called twos
#include <iostream> #include <vector> #include <algorithm> using namespace std; bool notmultipleOf2(int n) { return (n%2); } int main() { int numbers[]={1, 2, 3, 4, 5, 6, 7, 8, 9, 10}; vector<int> v(numbers,numbers+10); vector<int> twos; remove_copy_if (v.begin(), v.end(), back_inserter(twos),notmultipleOf2); }Create a function called notmultipleOf3 and call remove_copy_if using your function to create a vector called threes containing only multiples of 3. Then use set_intersection to create a vector containing only values that are multiples of both 2 and 3. - Create a vector of 20 integers, all different, where each integer is a random number betweeen 1 and 100 inclusive.
- How many numbers formed by permuting the digits 12345 are multiples of 11?
- A car milometer shows 15951. After 2 hours it shows another palindromic number. How fast was the car going on average? (use a loop to run through the integers from 15951, converting each number to a string and checking whether the string is palindromic. Once you've found a palindromic number, calculate the speed).
- For each 2 digit number, follow this procedure: Reverse it then add to the original number. Have you got a palindrome? If not then repeat the process until you do. Which initial 2 digit number takes the longest to become palindromic?
- At the end of a conference, attendees turn up one a minute at the taxi rank on the way to 1 of 5 stations. There are always taxis, and they'll go anywhere, but they'll only go if 3 people in the queue are all going to the same station. Simulate an hour's action and find the longest queue. (create an initially empty vector of ints. Use add_back to add a random integer between 1 and 5 (the item simulates an attendee). Use count to see if the vector has 3 items with the same value, using remove if 3 such items appear. Record the size of the vector)
Objects [ back to contents]
Let's create a class for storing information about under-graduates
class ugrad {
public:
string crsid;
string surname;
string directorOfStudies;
void introduce() { cout << "Hello, I'm " << surname << endl;};
};
Notice that it has a function inside it, so
ugrad test; test.surname="Mendel"; test.introduce();
would print "Hello, I'm Mendel". This function is best placed inside the class, giving students the chance to introduce themselves. We could create a vector in which to store these under-graduates
vector<ugrad> ugrads;
and write a program using these data structures. Suppose that we then decided to deal with post-graduates too, and we wanted to store crsid, surname and supervisor information about them. We could extend the data structures in various ways
- Write a separate class for pgrads
class pgrad { public: string crsid; string surname; string supervisor; void introduce() { cout << "Hello, I'm " << surname << endl;}; };The disadvantage of this is that we'd have 2 classes that we'd have to maintain in parallel - if we added a "year of birth" field to one, we'd have to remember to add it to the other too, which is asking for trouble. So let's consider another option - Write a class that has all the fields required, adding a field that shows whether the student's a ugrad.
class student { public: string crsid; string surname; string directorOfStudies; string supervisor; void introduce() { cout << "Hello, I'm " << surname << endl;}; bool ugrad; };This is better. The disadvantage of this is that some of the fields will be inappropriate (unused) for any particular student - not a disaster, but inelegant, and a waste of memory.
C++ (and many other languages) offers a way to "factorize" the fields using inheritance. First we create a class containing the common features
class student {
public:
string crsid;
string surname;
void introduce() { cout << "Hello, I'm " << surname << endl;};
};
Then we use this class as the basis for 2 other classes. The next bit of code means that ugrad will inherit all that the student class has, then add a field of its own. Similarly for pgrad.
class ugrad: public student {
public:
string supervisor;
};
class pgrad: public student {
public:
string directorOfStudies;
};
Now we can do
ugrad test; test.crsid="abc123"; test.surname="Carter"; test.supervisor="Smith";
and we could do a similar thing for a pgrad. If we wanted to add a new field common to both ugrad and pgrad, we'd add it to the student class. These classes form a hierarchy with student being the parent class and ugrad and pgrad being child classes.
Objects can help reduce errors and tidy up code. What you want to avoid is a primordial stew of global variables with routines floating in it that need the variables (see the diagram, left). This kind of organisation makes it harder to use the routines in other programs and leads to more errors. The O-O (Object-Oriented) approach (see the diagram, right) tries to keep data (and functions) tucked away safely inside objects.
![[globals bad, O-O good]](http://www-h.eng.cam.ac.uk/help/tpl/talks/C++course/stew.png)
Safety is further improved if the insides of objects aren't all visible. In the above code the word public appears a lot. Members can be made private, but that's for another document.
Complex numbers [ back to contents]
Using #include <complex> gives you access to complex numbers. You can choose the type of the components - here we'll use floats.
#include <complex>
#include <iostream>
using namespace std;
int main() {
complex<float> f1(1.5,2.7), f2(-5,8.3);
cout << "The norm of " << f1 << " is " << norm(f1) << endl;
cout << f1 << " raised to the power " << f2 << " is " << pow(f1,f2) << endl;
}
You can use complex numbers in containers. Here's a program that prints the square roots of the integers from -10 to -1
#include <complex> // for complex numbers
#include <iostream> // for printing
#include <vector> // for vector
#include <numeric> // for partial_sum
#include <cmath> // for sqrt
#include <algorithm> // for for_each
using namespace std;
complex<float> squareroot(complex<float> n) {
cout << sqrt(n) << endl;
}
int main() {
vector< complex<float> > v(10); // the space between the '>' characters is needed
fill(v.begin(), v.end(), -1);
partial_sum(v.begin(), v.end(),v.begin() );
for_each(v.begin(), v.end(), squareroot);
complex<float> answer=0.0;
cout << "Total=" << accumulate(v.begin(), v.end(), answer) << endl;
}
Using Objects with containers [ back to contents]
Here's some code that tries to sort students. Don't try to compile it!
#include <iostream>
#include <vector>
using namespace std;
class student {
public:
string crsid;
string surname;
void introduce() { cout << "Hello, I'm " << surname << endl;};
};
class ugrad: public student {
public:
string directorOfStudies;
};
int main() {
vector<ugrad> ugrads(3);
ugrads[0].crsid="cgf11"; ugrads[0].surname="Floyd"; ugrads[0].directorOfStudies="Alder";
ugrads[1].crsid="ogc71"; ugrads[1].surname="Carter"; ugrads[1].directorOfStudies="Alder";
ugrads[2].crsid="cgt77"; ugrads[2].surname="Taylor"; ugrads[2].directorOfStudies="Brown";
sort(ugrads.begin(), ugrads.end());
}
It won't compile because the sort function doesn't know how to compare ugrads. Suppose we want to sort in alphabetical order of crsid. sort depends on the < operator working with the elements that are being sorted. If the elements are strings or ints that's not a problem, but here the elements are a new type so we have to define what the < operator does in this situation. You do that by creating a function called operator< and giving that function references to two elements as in the next example. The notation may look alarming, but once you have a working example you can keep adapting it. Compile the following and run it to confirm that it works.
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
class student {
public:
string crsid;
string surname;
void introduce() { cout << "Hello, I'm " << surname << endl;};
};
class ugrad: public student {
public:
string directorOfStudies;
};
// the following function defines what the '<' operator should do when
// comparing 2 ugrads - it returns the comparison of their crsids
bool operator<(const ugrad& ugrad1,const ugrad& ugrad2 ) {
return ugrad1.crsid < ugrad2.crsid;
}
int main() {
vector<ugrad> ugrads(3);
ugrads[0].crsid="cgf11"; ugrads[0].surname="Floyd"; ugrads[0].directorOfStudies="Alder";
ugrads[1].crsid="ogc71"; ugrads[1].surname="Carter"; ugrads[1].directorOfStudies="Alder";
ugrads[2].crsid="cgt77"; ugrads[2].surname="Taylor"; ugrads[2].directorOfStudies="Brown";
sort(ugrads.begin(), ugrads.end());
cout << "Sorted students are ";
for (int i=0; i<ugrads.size();i++) {
cout << ugrads[i].crsid << endl;
}
}
This approach lets you create new types (ugrad for example) that correspond to the real-world entities you're trying to model, and lets you use off-the-shelf routines to process them.
Object Exercises [ back to contents]
- Add an int field to the student class to store the year of birth. Copy the last example and give each student a year of birth, then change the sort function so that it sorts according to the year of birth.
- Add a new staff class with crsid, surname and division fields. Make the division field a string (we have div "A", "B" ... "F" and a few others). Create details for a few staff members and sort according to their division. Make each staff member introduce themselves in order of their division.
Efficiency [ back to contents]
Sorting
 The sorting in the previous section worked ok, but there are problems
with it if we want to sort all the students and do so efficiently.
The sorting in the previous section worked ok, but there are problems
with it if we want to sort all the students and do so efficiently.
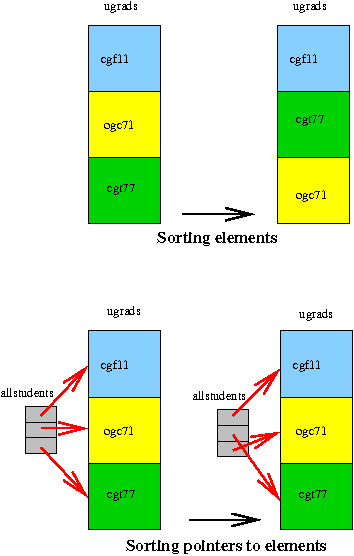
- The elements of the ugrads vector are being moved around so that they're in order. If each element were large (an image, for example) this would take a long time. In many cases all this extra work isn't necessary - we just want to know what the right order is, not physically put everything in the right order.
- We'd like to extend the previous program to sort all the students whether they're ugrads or pgrads. C++ is quite strict about mixing different types of variables. Containers like vector have to contain elements that are all the same type, so we can't put all the ugrads and pgrads in one big vector and sort them
However, though pgrad and ugrad are different, they're related - they have the same parent class, namely student. We can take advantage of this, creating a vector of pointers to students.
vector< student* > allstudents;
The advantage of this is that a pointer to a student can actually point to a ugrad or pgrad because both ugrads and pgrads are students. This makes the following possible
// extend the allstudents vector one element at a time
for (int i=0; i<ugrads.size();i++)
allstudents.push_back(&(ugrads[i]));
allstudents now contains pointers to all the ugrads. We could add pgrads in the same way. If we sorted allstudents we'd sort these pointers, but these pointers are like the addresses of the elements, so sorting them isn't useful to us. We want the sorting to be done according to the crsid of the student being pointed to. Fortunately the sort routine lets us provide our own comparison function. If we use
sort(allstudents.begin(), allstudents.end(), mysort);
then whenever 2 elements in allstudents need to be compared, mysort is called. If we use the following code to define mysort, sorting should work the way we want.
bool mysort(const student* student1, const student* student2) {
return student1->crsid < student2->crsid;
};
Here's the complete program. allstudents is created empty. To it is added pointers to all the elements in ugrads and pgrads. Then the pointers are sorted so that the 1st pointer points to the first student (the student whose crsid is first in the alphabet), the 2nd pointer points to the second student, and so on. The student information isn't being moved around, so even if we added a lot more information on each student, the code wouldn't be slower.
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
class student {
public:
string crsid;
string surname;
void introduce() { cout << "Hello, I'm " << surname << endl;};
};
class ugrad: public student {
public:
string directorOfStudies;
};
class pgrad: public student {
public:
string directorOfStudies;
};
bool mysort(const student* student1, const student* student2) {
return student1->crsid < student2->crsid;
};
int main() {
vector< student* > allstudents;
vector<ugrad> ugrads(3);
ugrads[0].crsid="cgf11"; ugrads[0].surname="Floyd"; ugrads[0].directorOfStudies="Alder";
ugrads[1].crsid="ogc71"; ugrads[1].surname="Carter"; ugrads[1].directorOfStudies="Alder";
ugrads[2].crsid="cgt77"; ugrads[2].surname="Taylor"; ugrads[2].directorOfStudies="Brown";
vector<pgrad> pgrads(3);
pgrads[0].crsid="ahy91"; pgrads[0].surname="Young"; pgrads[0].directorOfStudies="Brown";
pgrads[1].crsid="juh70"; pgrads[1].surname="Hughes"; pgrads[1].directorOfStudies="Drake";
pgrads[2].crsid="ggh72"; pgrads[2].surname="Hawks"; pgrads[2].directorOfStudies="Evans";
for (int i=0; i<pgrads.size();i++)
allstudents.push_back(&(pgrads[i]));
for (int i=0; i<ugrads.size();i++)
allstudents.push_back(&(ugrads[i]));
sort(allstudents.begin(), allstudents.end(),mysort);
cout << "Sorted allstudents are " << endl;
for (int i=0;i<allstudents.size(); i++) {
cout<< allstudents[i]->crsid << endl ;
}
}
Data Structures
Items could be stored in vectors or lists. Which is the most efficient? It depends on what you're going to do with the items.
- In a C++ vector the items are stored in an array. This makes it easy to navigate through the vector and jump to a particular item, but removing an item in the middle of the vector can involve a lot of work because other items need to be moved to fill in the gap
- A C++ list is a linked list. The items may not be next to each other in memory - there's a link (a pointer) from one item to the next. This means that accessing elements isn't that fast (you can't for example jump to the 6th item; you need to access all the previous ones too, following the pointers). The advantage of linked lists is that deletion is easy - for example, to delete the 6th item you just make the 5th item point to the 7th item; no items need to be moved.
You need a way to measure efficiency - the amount of memory used or the amount of time used? Here's we'll focus on speed. Even with fairly small programs, speed can become an issue. The program below keeps inserting two "999" values just after the first item in containers. When I run the code, the list version is over 5 times faster than the vector version, though both versions are equally easy to write.
#include <iostream>
#include <sys/time.h>
#include <vector>
#include <list>
using namespace std;
long microseconds();
long microseconds() {
struct timeval tv;
gettimeofday(&tv,0);
return 1000000*tv.tv_sec + tv.tv_usec;
};
long time1;
int main() {
// Using vector
vector<int> v;
for (int i=0;i<3;i++)
v.push_back(i);
time1=microseconds();
for (int i=0;i<1000;i++) {
v.insert (v.begin(), 999,2);
}
cout << "Vector time:" << microseconds() - time1 << endl;
// Using list
list<int> l;
for (int i=0;i<3;i++)
l.push_back(i);
time1=microseconds();
for (int i=0;i<1000;i++) {
l.insert (l.begin(), 999,2);
}
cout << "List time:" << microseconds() - time1 << endl;
}
The following example shows how to time some finds and deletions. A vector is filled then one by one the elements are removed.
#include <iostream>
#include <algorithm>
#include <sys/time.h>
#include <vector>
using namespace std;
long microseconds();
long microseconds() {
struct timeval tv;
gettimeofday(&tv,0);
return 1000000*tv.tv_sec + tv.tv_usec;
};
long time1;
int main() {
vector<int> v;
vector<int>::iterator vit;
for (int i=0;i<10000;i++)
v.push_back(i);
time1=microseconds();
for (int i=0;i<10000;i++) {
vit=find(v.begin(), v.end(),i);
v.erase(vit);
}
cout << "Vector time:" << microseconds() - time1 << endl;
}
Efficiency Exercises [ back to contents]
- Compare the speed of the above program with the speed of a program which uses a list instead of a vector. Then remove the erase command and compare again. What difference does that make?
- Change the student-sorting program so that it sorts according to the student surname.
- Change the student-sorting program so that it sorts according to the students' director of studies. If 2 students have the same director of studies, sort according to the student surname.
Maps [ back to contents]
When you are using a C++ array of strings, you are mapping from integers to strings, but other mappings aren't so easy with arrays - for example, if you were creating a phone directory you might want to create a mapping between names and numbers. This is where maps are useful. A map in C++ defines a mapping between any 2 types of items - a key and a value. In maps, the keys are unique. C++ offers multimaps which can have duplicate keys. Here's a little example of using map.
#include <iostream>
#include <map>
#include <string>
using namespace std;
int main ()
{
// the next line creates a mapping from strings to strings
map<string,string> car;
car["Smith"]="Ford";
car["Jones"]="Jaguar";
cout << "Smith's car is a " << car["Smith"] << endl;
cout << "Jones' car is a " << car["Jones"] << endl;
}
Like other containers, map has size, begin and end member functions. The code is quite readable once you've set up the mapping.
The following code makes a frequency count of the characters in a string and prints the answers. The items in a map are pairs (pair is a standard C++ library type with members called first and second), so in this case, for_each is passed a <char,int> pair from which the components can be extracted.
#include <iostream>
#include <algorithm>
#include <map>
using namespace std;
map<char,int> frequencies;
void counting(char c) {
// add one to the frequency-count for character c.
frequencies[c]++;
}
void printing(pair<char,int> the_pair){
cout << the_pair.first << " " << the_pair.second << endl;
}
string s="classes, containers and maps";
int main ()
{
// give each letter in s to the counting function, then
// print the resulting frequencies
for_each(s.begin(), s.end(), counting);
for_each(frequencies.begin(), frequencies.end(), printing);
}
Map Exercises [ back to contents]
- Write a program that asks the user
Type a name (or "exit" to print a list and exit):
If that name's already been typed in, display the associated phone number, otherwise ask for a number to be typed in and store the name and number. Then ask for another name until the user types "exit". The code need only be about 30 lines long. You needn't check that the number contains only digits. A useful map would be map<string,string> addressbook, using find and for_each to do the work.
Multimaps [ back to contents]
Here's a little multimap example. Note that you need to add the elements in a different way - you need to use pair to create pairs of values to add to the mapping.
#include <iostream>
#include <map>
#include <string>
using namespace std;
int main ()
{
multimap<string,string> car;
car.insert(pair<string,string>("Smith","Ford"));
car.insert(pair<string,string>("Jones","Jaguar"));
car.insert(pair<string,string>("Smith", "Nissan"));
cout << "Smith has " << car.count("Smith") << " cars" << endl;
}
Listing the cars that Smith owns isn't so easy
#include <iostream>
#include <map>
#include <string>
using namespace std;
int main ()
{
multimap<string,string> car;
multimap<string,string>::iterator it;
pair<multimap<string,string>::iterator,multimap<string,string>:: iterator> two_its;
car.insert(pair<string,string>("Smith","Ford"));
car.insert(pair<string,string>("Jones","Jaguar"));
car.insert(pair<string,string>("Smith", "Nissan"));
two_its=car.equal_range("Smith");
cout << "Smith owns";
for (it=two_its.first; it!=two_its.second; ++it)
cout << " " << (*it).second;
cout << endl;
}
More about Objects [ back to contents]
If your program deals with people, you might want to create objects designed to store information about people. Here's a simple example, similar to the student class used earlier
class person {
public:
float height;
string name;
};
This piece of code doesn't create a person object, but makes it possible to create one. You can now create a person by doing
person p;
Once you've created a person you can then fill in the details. E.g.
p.height=1.73; p.name="simon";
As we've seen before, an object can also have actions (member functions) and data. For example,
class person {
public:
float height;
string name;
void sayhello() { cout << "hello!\n"; };
};
gives each person an extra ability which can be called by doing
person p; p.sayhello();
Whenever an object is created, a special action (called a "constructor") is run. If you don't write one yourself, a default one is called. The constructor function has the same name as the class itself so if we want to write our own we could say
class person {
public:
float height;
string name;
void sayhello() { cout << "hello!\n"; };
person() { sayhello(); cout << "I've just been created\n";};
};
So now,
person p; person q;
would produce the output
hello!
I've just been created
hello!
I've just been created
This constructor takes no arguments. We could also provide a constructor that takes one argument
person(string n) { name=n; sayhello();
cout << "I've just been created\n";};
which would give us the chance to name people as we create them by doing something like
person p("eve");
When an object is destroyed, a "destructor" function is called. For our object the destructor would be called ~person, but before we can show it in action we need to set up a situation where people die.
#include <iostream>
#include <string>
using namespace std;
class person {
public:
float height;
string name;
void sayhello() { cout << "hello! I'm " << name << "\n"; };
person(string n) { name=n; sayhello(); cout << "I've just been created\n";};
person() { name="NOBODY"; cout << "I've just been created\n";};
~person() { cout << name << " is about to die\n";};
};
void testfunction() {
person p("adam");
}
int main() {
person q("eve");
testfunction();
}
This re-uses much of the earlier code (the original constructor now sets name to NOBODY for safety's sake). Here, a person is created in the main routine then testfunction is called. In testfunction another person is created, but the lifetime of that person is only as long as the lifetime of the testfunction routine, so adam dies before eve. If you compile and run this you'll get
It might be useful to know how many persons exist at any particular moment. The variables like name and height are unique to each object but it's possible to create a single variable that all the persons can access. The syntax isn't simple but the facility's useful. Note the use of static and how the variable is created outside of all functions. We can use this variable as a counter, adding 1 to it when a person is created and subtracting 1 when a person dies. Here's the revised code -
#include <iostream>
#include <string>
using namespace std;
class person {
static int howmany; // all persons share this one variable
public:
float height;
string name;
void sayhello() { cout << "hello! I'm " << name << "\n"; };
person(string n) {
howmany++;
name=n;
sayhello();
cout << "I've just been created. There are now "
<< howmany << " of us.\n";
};
person() {
howmany++;
name="NOBODY";
cout << "I've just been created. There are now "
<< howmany << " of us.\n";
};
~person() {
howmany--;
cout << name << " is about to die, leaving "
<< howmany << " of us\n";
};
};
void testfunction() {
person p("adam");
}
// The howmany variable belongs to the class.
int person::howmany=0;
int main() {
person q("eve");
testfunction();
}
This may already look like quite a long and complicated program. On the plus side
- the longest routine is only 6 lines long
- the "top level" code (in main and testfunction) hasn't required changing. You'll find that much of the work in C++ programs involves developing the objects so that the "top level" is uncluttered.
On the minus side, the counting functionality isn't finished - there are ways of creating objects that we haven't taken into account. To see this, add the following line to the end of main
person r=q;
If you compile and run this you get additional output
The death of r the "eve" clone has been registered, but not the clone's creation. When a new person is created by copying an existing one, it uses a different constructor function called the "copy constructor". If you add the following copy constructor to the person class, things will be better. Again, the notation isn't obvious, but you can copy this example.
person(const person&) {
howmany++; sayhello();
cout << "I've just been created. There are now "
<< howmany << " of us.\n";
}
More Object Exercises [ back to contents]
- There's some duplicated code in the person-based code above which (following CUED's 3F6 course notes) is a bad thing. Try to factorise the code.
- Write a program with a function that takes a person as an argument. First pass by value then pass by reference, noting how the count changes.
- Sometimes it's useful to create "singleton" classes - classes where only one object of that type can exist. Adapt the code so that person becomes a singleton class.
Exceptions [ back to contents]
 Expect the unexpected. In C, every call had to be checked to see if it returned an error value. C++ exceptions are
an alternative to traditional techniques when return-values are insufficient,
inelegant, or error-prone. They're used by standard C++ routines and you can make your routines create them too. Three keywords are involved
Expect the unexpected. In C, every call had to be checked to see if it returned an error value. C++ exceptions are
an alternative to traditional techniques when return-values are insufficient,
inelegant, or error-prone. They're used by standard C++ routines and you can make your routines create them too. Three keywords are involved
- try - specifies an area of code where exceptions will operate
- catch - deals with the exceptional situation produced in the previous try clause.
- throw - reports news of an exceptional situation
When an exception is 'thrown' it will be 'caught' by the local catch clause if one exists, otherwise it will be passed up through the call hierarchy until a suitable catch clause is found. The default response to an exception is to terminate, so if you don't catch an exception, your program will end.
There are many types of standard exception objects - they form a class hierarchy. To use the standard ones (or inherit from them) you need to have #include <exception> or #include <stdexcept> in your code. Alternatively you can throw something of your own making. Note that
- "catch" routines are like other C++ routines in that there can be several of them in the same context taking different arguments
- Once the exception has been caught and dealt with, the program continues from just after the "catch" routine. If your "try" region surrounds the whole program this means that execution will end, but you can put "try{...}" around a localised region so that execution continues, as in the following example.
#include <iostream>
#include <string>
using namespace std;
// Create a customised type of object to throw
class Ball {
public:
int number;
string message;
};
int main() {
for (int i=1;i<4;i++) {
try {
switch (i) {
case 1: throw 999 ;
case 2: throw "help!";
case 3: Ball *ball = new Ball;
ball->number =999;
ball->message="help!";
throw ball;
}
} // end of try
catch(int errornumber) {
cerr << "error number is " << errornumber << endl;
}
catch (const char* errormessage) {
cerr << "error message is " << errormessage << endl;
}
catch(Ball *b) {
cerr << "error " << b->number << " - " << b->message << endl;
}
} // end of for loop
}
By default in the standard library, errors involving streams don't generate exceptions. Exceptions can be enabled individually though. Here's a way to check whether file-opening succeeds using exceptions. Note that the standard exception object has a what member function that returns an informative string
#include <iostream>
#include <fstream>
#include <exception>
using namespace std;
int main() {
try {
fstream fin;
// Enable exception
fin.exceptions( fstream::failbit );
// The next line will throw an exception if "test" doesn't exist
fin.open("test");
}
catch (std::exception &e) {
cout << "Exception caught: " << e.what() << endl;
}
}
Containers use exceptions. A common error when using arrays is trying to access an element that doesn't exist - changing the 100th element of an array that's of size 10 might crash the program immediately or might have more mysterious later consequences. vectors have an at member function that you can use instead of []. Its advantage is that it generates an exception if the index is out of range.
#include <vector>
#include <iostream>
#include <stdexcept>
using namespace std;
int main() {
vector<int> v(3);
try{
for (int i=1; i<=3; i++)
v.at(i)=i; //v[i]=i wouldn't generate an exception
}
catch(out_of_range& e) {
cout << e.what() << endl;
}
}
Exceptions become more obviously useful in big programs with many functions. Suppose you have a low-level routine called routine4 which might need to communicate an error message to a top-level routine called routine1. routine1 doesn't call routine4 directly but via routine2 and routine3. The traditional way to determine the success or otherwise of a routine is to check the value that it returns, but in this case that means making the value thread back up through routine3 and routine2 (see the example on the left) which complicates the code. The example on the right shows how using exceptions can make the intermediate routines simpler - a problem in routine4 can be directly reported to the top-level error-handing catch routine.
| Using error codes | Using exceptions |
| #define OK 1 | try{ |
| int routine4(){ | void routine4(){ |
| int return_value; | |
| // Do something. If it goes wrong, | // Do something. If it goes wrong, |
| // tell routine1 by setting | // tell routine1 by throwing a message |
| // return_value accordingly | |
| return(return_value); | throw("help!"); |
| } | } |
| int routine3(){ | void routine3(){ |
| int return_value; | |
| return_value=routine4(); | routine4(); |
| if (return_value != OK) | |
| return(return_value); | |
| ... | ... |
| } | } |
| int routine2(){ | void routine2(){ |
| int return_value; | |
| return_value=routine3(); | routine3(); |
| if (return_value != OK) | |
| return(return_value); | |
| ... | ... |
| } | } |
| int routine1(){ | void routine1(){ |
| int return_value; | |
| return_value=routine2(); | routine2(); |
| if (return_value != OK) | |
| // try to recover | |
| } | } |
| } // end of the try | |
| catch(string& e){ | |
| // try to recover | |
| } |
Utilities [ back to contents]
Converting between integer and string
The following code converts between strings and integers without much error-checking
#include <iostream>
#include <sstream>
#include <string>
using namespace std;
string convertToString(const int x) {
ostringstream o;
if (o << x)
return o.str();
return "conversion error";
}
int convertFromString(const string& s) {
istringstream i(s);
int x;
if (i >> x)
return x;
return -999; // return an error code
}
int main() {
int f=718;
string s=convertToString(f);
cout << "Length of " << f << " when converted to a string is " << s.size() << endl;
cout << "s= " << convertFromString(s) << " when converted to an int" << endl;
}
Timing
#include <iostream>
#include <sys/time.h>
using namespace std;
long microseconds();
// This function returns the number of microseconds since 1st Jan 1970
long microseconds() {
struct timeval tv;
gettimeofday(&tv,0);
return 1000000*tv.tv_sec + tv.tv_usec;
}
int main() {
cout << microseconds() << endl;
sleep(2); // sleep about 2 seconds
cout << microseconds() << endl;
}
Random Integers
#include <cstdlib>
// return a random integer between 1 and n
int RandomInt(int n)
{
return 1 + (random() % n);
}
int main() {
srandom(time(0)); // call this once to initialise the randomiser
int r= RandomInt(7);
}
Troubleshooting [ back to contents]
Throughout this document I've glossed over some difficulties and details. In this section I'll try to address some of them.
Limitations of algorithms
It would be nice if all the algorithms worked with all the containers, but they don't. If for example you try to sort or random_shuffle a list rather than a vector, you'll get an error message, but the message won't tell you what the problem is. The trouble is that some algorithms require certain features that only some containers have. In particular, random_shuffle requires the ability to jump anywhere in the container - it requires the container to have "random-access iterators". Vectors and arrays have these iterators, but a list doesn't.
You may find STL Containers or C++ Containers Cheat Sheet useful - the latter has tables and flow-charts. "random-access iterators" are available for the containers where the a[n] notation is available, which according to their table restricts random_shuffle usage to vectors, double-ended queues, and strings. If you want to sort a list you could copy it to a vector, sort it, then copy it back.
There are also limitations on the type of functions you can use with the algorithms. For example, on the algorithms exercise which dealt with multiples, the routine used with remove_copy_if could only take one argument (namely the element being tested) so you had to write a new function for each value you were trying to eliminate multiples of. Ways round this limitation exist, but are beyond the scope of this document - see the templates and bind2nd pages. To give you a flavour of what's possible, here's the code provided in the exercise written in a more general (but more advanced) way using functors.
#include <iostream>
#include <functional>
#include <vector>
#include <algorithm>
using namespace std;
int main() {
int numbers[]={1, 2, 3, 4, 5, 6, 7, 8, 9, 10};
vector<int> v(numbers,numbers+10);
vector<int> twos;
remove_copy_if (v.begin(), v.end(), back_inserter(twos), bind2nd(not2(modulus()),2));
}
Compiler error messages
These can be hard to understand. If you're given a line number that refers to your source code, make the most of it - it may be the only clue you get. Here are some tips
- Check for silly errors first - they're easy to make when you're trying something new
- Ensure you've #included the appropriate files
Useful Links [ back to contents]
- © 2011 University of Cambridge Department of Engineering
Information provided by Tim Love (tpl) (Last updated: June 2011) - Privacy
- Accessibility