Faster C++
This document starts by giving some background information before mentioning some methods that can deliver big (order of magnitude) improvements. Then small-scale efficiency tricks will be covered.
How computers work
Memory
Memory matters to the speed of a program. Improvements in memory speed haven't kept pace with CPU improvements - the fastest CPU operation can take the time light travels a foot. Nowadays it may be faster to do a calculation again than to store the answer for later use.
There's a memory hierarchy -
- CPU, registers
- caches (multilevel)
- RAM, swap
- Disk, mass storage
The smallest, fastest memory is in the CPU. Much more memory is on the disc (mass storage), but it's slower. One experiment determined that the CPU is 8* faster than the L2 cache which is 256* faster than RAM which is 80* faster than Disc, but every machine's different.
Best case? - keep the CPU busy by using fast memory, where recently used values, or memory adjacent to those values, might be stored.
Worst case? - keep jumping around in memory.
CPU
Nowadays there are "multi-core" CPUs, and computers can have more than one CPU (our Linux Servers each have 4 quad-core CPUs). Unless you're a low-level programmer though, you won't be able to take explicit advantage of this potential for parallel programming. See the Parallel Programming page if you're interested.
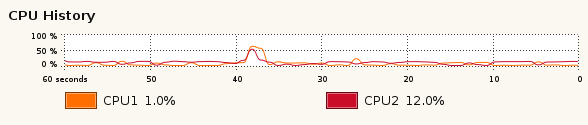 On the teaching system you can get a rough idea of a programs' CPU and memory
usage by running the Computer panel's system monitor. Here's the CPU part of the monitor's output for a DPO machine
On the teaching system you can get a rough idea of a programs' CPU and memory
usage by running the Computer panel's system monitor. Here's the CPU part of the monitor's output for a DPO machine
Especially for specialised number-crunching areas, power can be obtained fairly cheaply. Some groups in the department use big clusters of cheap machines to run programs, but unless you belong to those groups you won't be able to use these machines. Alternatively, in the Guardian (Feb 2008) an academic said he could run a simulation 130 times faster on a PlayStation 3 (which has several CPUs/accelerators) than on his desktop PC. Some CUED people use CUDA (a library that uses an nVidia graphics board) to get 10x speed-up. C++ AMP (Accelerated Massive Parallelism) is a set of language extensions to standard C++ to take advantage of GPUs. They excel at highly parallel tasks (without much thread divergence) that emphasize single-precision floating point calculations over memory access and work best when threads all access the same memory locations or there's a regular small spacing between memory locations accessed by different threads.
Basic principles
- A very common piece of advice is "Delay optimization as much as possible, and don't do it if you can avoid it.", Donald Knuth said, "premature optimization is the root of all evil."
- A very common piece of advice is "Measure to find out where the bottleneck is, and optimise that."
- Select appropriate data structures.
- Pick sensible algorithms - if you're sorting or searching, don't just use the first routine you come across.
- I/O is slow
Profiling
Don't assume that calculations with floats are faster than calculations with doubles - or even with ints. Don't even assume that it's faster to store a value for future use than to recalculate it. Profile your code in as realistic conditions as possible.
With g++ you'll need to compile using the "+g" option, run your program (called snail for example), then run prof snail. You'll get output looking a little like this
%Time Seconds Cumsecs #Calls msec/call Name 32.4 0.35 0.35 __strlen20 23.1 0.25 0.60 5770000 0.00 _strlen 20.4 0.22 0.82 10000 0.02 slow 11.1 0.12 0.94 10000 0.01 fast 10.2 0.11 1.05 _mcount 1.4 0.01 1.06 _monstartup
Containers
They make life easy, offering more than one way of doing something, but if used thoughtlessy, the resulting code will be slow.
- If a container provides a member function that duplicates a generic STL algorithm it is likely that the member function is more efficient. In the following, the 1st loop takes 50% longer when I run it.
#include <iostream> #include <string> #include <sys/time.h> using namespace std; long microseconds() { struct timeval tv; gettimeofday(&tv,0); return 1000000*tv.tv_sec + tv.tv_usec; } int main() { string a="hello"; string b="goodbye"; long t1=microseconds(); for (int i=0;i<10000;i++) { swap(a,b); } cout << microseconds() - t1 << endl; t1=microseconds(); for (int i=0;i<10000;i++) { a.swap(b); } cout << microseconds() - t1 << endl; }However, the 2nd loop in the next example takes twice as long as the 1st loop.
#include <iostream> #include <string> #include <set> #include <algorithm> #include <sys/time.h> using namespace std; long microseconds() { struct timeval tv; gettimeofday(&tv,0); return 1000000*tv.tv_sec + tv.tv_usec; } int main() { string A[10000]; for (int i=0;i<10000;i++) { A[i]="hello"; } set<string> setA(A, A+10000); set<string>::iterator it1; long t1=microseconds(); for (int i=0;i<10000;i++) { it1=find(setA.begin(), setA.end(),"goodbye"); } cout << microseconds() - t1 << endl; t1=microseconds(); for (int i=0;i<10000;i++) { it1=setA.find("goodbye"); } cout << microseconds() - t1 << endl; }
Note that container-based code responds well to optimisation.
Compiler options
It's important to tell the compiler as much as you can about your code so that it can optimise well. Use `const' keywords whenever you can. See man pages for compiler directives. In g++ there are over 200 of them - e.g. -fbranch-probabilities, -fexpensive-optimizations -ffast-math, -fno-trapping-math, -funsafe-math-optimizations, -freorder-functions, -funroll-all-loops. Using +O4 does aggressive, time-consuming optimisation.
New compiler releases can have greatly improved optimisers. The simpler the code, the better chance the compiler has of optimising it - which is why it doesn't alway pay off to try the clever tricks later in this document. The table in the Nasty tricks shows what speed-ups can be achieved. Order of magnitude speed-ups are possible.
Cache-friendliness
Try this code. The second loop is 50% slower than the first on a Mac and Dell that I tried.
#include <iostream>
#include <vector>
#include <sys/time.h>
using namespace std;
// This function returns microseconds elapsed since the dawn of computing
// (1st, Jan, 1970). Don't worry about how it works
long microseconds() {
struct timeval tv;
gettimeofday(&tv,0);
return 1000000*tv.tv_sec + tv.tv_usec;
}
int a[1000][1000];
int b[1000][1000];
int c[1000][1000];
int d[1000][1000];
int main(){
int tmp;
long t1=microseconds();
for (int i=0;i<1000;i++)
for (int j=0;j<1000;j++)
tmp=a[i][j]*b[i][j];
cout << microseconds()-t1 << endl;
t1=microseconds();
for (int i=0;i<1000;i++)
for (int j=0;j<1000;j++)
tmp=c[j][i]*d[j][i];
cout << microseconds()-t1 << endl;
}
The difference is that loop1 goes through the matrix row by row rather than column by column. The matrix is stored row by row, so loop1 accesses successive memory addresses. Since data transfers are done in blocks, this will involve fewer block transfers.
Function calls
Arguments
Suppose you have
int a=7; a=triple(a);
where the triple function is
int triple(int x) {
return 3*x;
}
When "triple" is called, the value of the "a" argument is copied to "x", then at the end of the function the return value is copied into "a". That's 2 copies that would be avoided were references used -
triple(a);
...
void fun(int& x) {
...
x*=3;
}
In this example only an integer is copied, but if there are many big objects, the extra copying can be expensive. Using optimisation in the code below, the 2nd loop is 50 times faster than the 1st.
#include <iostream>
#include <string>
#include <sys/time.h>
using namespace std;
long microseconds() {
struct timeval tv;
gettimeofday(&tv,0);
return 1000000*tv.tv_sec + tv.tv_usec;
}
string valuecrossout(string s) {
s[0]='x';
s[1]='x';
return s;
}
void refcrossout(string& s) {
s[0]='x';
s[1]='x';
}
int main() {
string a="hello";
long t1=microseconds();
for (int i=0;i<10000;i++) {
a= valuecrossout(a);
}
cout << microseconds() - t1 << endl;
t1=microseconds();
for (int i=0;i<10000;i++) {
refcrossout(a);
}
cout << microseconds() - t1 << endl;
}
Virtual functions
These are slower to call though may lead to neater code.
Coding
Once you get down to the level of code, there are trade-offs - Speed/Size/Readability
- Loops - Deeply nested loops merit particular attention.
- Do nothing unnecessary in the loop.
- Keep loops small (some machines have an `instruction cache' (the DPO machines have 16k of data cache and 12k of execution cache (L1) per core) so that recent instructions can be quickly recalled. If a loop fits inside the cache, you'll benefit.
- as a condition compare with 0.
- 'unroll' them (i.e. use a list instead of a loop)?
- exceptions and virtuals are slower. Adding "throw()" just before the body of a function tells the compiler that the function won't use exceptions, making the code perhaps 1% faster.
- Create variables as late as possible and initialise them at creation time - this
int max=0; if (x==7) { Person p(23); ... max=p.age; }is preferable to thisPerson p; int max; max=0; if (x==7) { p.age=23; ... max=p.age; } - Passing parameters - If you're passing very large items by value, memory requirements (and hence time requirements) increase. It might be helpful to make very big data-structures global.
- Avoid recursion.
- Arithmetic - See
- Floating-Point Basics (Pete Becker)
- What Every Computer Scientist Should Know About Floating-Point Arithmetic
- Use look-up tables instead of function calls for sin(x), etc.
- Use bit-shift rather than + or - rather than * or /.
#include <iostream> #include <sys/time.h> using namespace std; // This function returns microseconds elapsed since the dawn of computing // (1st, Jan, 1970). Don't worry about how it works long microseconds() { struct timeval tv; gettimeofday(&tv,0); return 1000000*tv.tv_sec + tv.tv_usec; } int a[10000][10000]; int b[10000][10000]; int main(){ for (int i=0;i<10000;i++) for (int j=0;j<10000;j++) a[i][j]=b[i][j]=i+j*i; int tmp; long t1=microseconds(); for (int i=0;i<10000;i++) for (int j=0;j<10000;j++) tmp=a[i][j]*b[i][j]; cout << "Multiplication "<< microseconds()-t1 << endl; t1=microseconds(); for (int i=0;i<10000;i++) for (int j=0;j<10000;j++) tmp=a[i][j]+b[i][j]; cout <<"Adding "<< microseconds()-t1 << endl; t1=microseconds(); for (int i=0;i<10000;i++) for (int j=0;j<10000;j++) tmp=a[i][j]*b[i][j]; cout << "Multiplication "<< microseconds()-t1 << endl; t1=microseconds(); for (int i=0;i<10000;i++) for (int j=0;j<10000;j++) tmp=a[i][j]+b[i][j]; cout <<"Adding "<< microseconds()-t1 << endl; }I gotMultiplication 258647 Adding 269356 Multiplication 258875 Adding 269829
without optimising. With optimisation I gotMultiplication 30606 Adding 31062 Multiplication 30756 Adding 30799
Usingfloats instead ofints made no difference.With this code
#include <iostream> #include <sys/time.h> using namespace std; long microseconds(); long microseconds() { struct timeval tv; gettimeofday(&tv,0); return 1000000*tv.tv_sec + tv.tv_usec; }; long time1; // Results acculumated and printed to ensure that the compiler won't // optimise away unnecessary calculations int main() { int i1=3,i2=4,i3; float f1=3,f2=4,f3; time1=microseconds(); for (int i=0;i<10000;i++) for(int j=0;j<10000;j++) i3+=i1+i2; cout << "Time to add ints:" << microseconds() - time1 << ". i3="<< i3 << endl; time1=microseconds(); for (int i=0;i<10000;i++) for(int j=0;j<10000;j++) f3+=f1*f2; cout << "Time to multiply floats:" << microseconds() - time1 << ". f3="<< f3 << endl; }I got this with no optimisation
Time to add ints:225330. i3=700000000 Time to multiply floats:302071. f3=2.68435e+08
, this using "-O"
Time to add ints:48830. i3=700000000 Time to multiply floats:312950. f3=2.68435e+08
and this using "-O"
Time to add ints:0. i3=700000000 Time to multiply floats:37905. f3=1.07374e+09
- Malloc
- If you're using malloc a lot, look up the options to tune malloc.
- Reduce `paging' by keeping program small or at least stop it nonsequentially accessing memory.
Nasty Tricks
See C++: Nasty Tricks if you're desperate.
See Also
- Optimizing C++/Writing efficient code
- C++ Optimization Strategies and Techniques (contains examples and timings)
- Performance Optimization (Dennis de Champeaux)
- Slow containers - a short note about a particular issue, but the comments are more widely applicable
- a tech report (202 pages) on C++ performance. It aims to " debunk widespread myths about performance problems, to present techniques for use of C++ in applications where performance matters", etc.
- Techniques for Scientific C++ has many speed-up suggestions
- Scientific Computing is rather old but many of the points still apply. It compares C++ and Fortran.
- C++ Optimisation is part of a book about writing faster C++ code.
- Writing Efficient C and C Code Optimization (Koushik Ghosh)