Parsing arithmetic expressions - Bison and Flex
People sometimes ask if there's a C++ library function that given a string like "2+(3*4)" will return its value as a number. There's isn't such a function, but writing one is possible. This document illustrates how it can be done in about 50 lines of code using flex and bison. These programs generate source code to parse text that's structured (a computer program, for example, or a configuration file, or a maths expression). They're not trivial to use, but they're less error-prone than hand-crafted alternatives. The minimum of details will be explained here - with luck you should be able to adapt the programs in small ways for your own purposes.
Before introducing the example, I'll briefly deal with parsing in general, and with "regular expressions".
Parsing
If you've ever written a program that reads text lines that are in particular formats, then you've written a sort of parser. Compilers include more sophisticated parsers. In general the first stage in parsing is "lexical analysis" (or "scanning") - reading in a string of characters and outputing a stream of strings and tokens. In this phase white space is usually deal with (as are comments), and keywords are replaced by symbols. lex or flex produce code for a function that does this, called yylex().
The second phase builds these elements (often known as lexemes) into expressions or phrases and "makes sense" of them. Yacc ("yet another compiler-compiler") and bison (so named because it isn't a Yak) produce code for a function called yyparse() that does this.
Both phases need to detect errors. That's not so hard, but it's difficult to produce error reports that are useful to humans, which is where hand-crafted parsers sometimes have an edge over auto-generated ones.
Sophisticated parsers come in several types. You don't need to know about the technical details, but a little of the vocabulary is useful to know about, in case things go wrong. When a grammar is described as LR(1) the first L means that the input is read from Left to right - i.e, from the start of the file (or line) to the end. The R means that the parser produces right-most derivations. The alternative to this is L (left-most derivations)
- Right-derivation parsers are "bottom-up" - items are read and combined into bigger units which are then reduced to a value.
- Left-derivation parsers are "top-down". They start by expecting to read a single entity (a program, say). They know the format of this entity so they know what component to expect next. They work by expanding (filling in the details of) what they're next expecting.
The number in brackets after the LR indicates how far the parser needs to look ahead before being able to understand the token it's on. bison can only understand grammars where looking one token ahead removes ambiguities.
bison essentially produces LR(1) parsers. Not all grammars can be dealt with by such parsers ("C++ grammar is ambiguous, context-dependent and potentially requires infinite lookahead to resolve some ambiguities" - Meta-Compilation for C++)
Regular Expressions
Regular Expressions are used with flex. You can think of Regular Expressions as a more sophisticated form of wildcard characters. On the Unix command line, ? matches a single character, and * matches 0 or more characters, so if you wanted to list all the files whose names have an x as the 4th letter, you could type ls ???x*. Regular Expressions use a different notation and can express more complex patterns. Here's a list of the features used on this page
- . matches a single character
- [ ] matches any of the characters in the brackets. For example, [abc] matches a, b or c
- - represents intervening characters, so [0-9] matches any digit
- + means "one or more of the preceeding item", so [0-9]+ matches any integer
- * means "zero or more of the preceeding item"
- ? means the preceeding items is optional
- | means "or"
- () group things
- {} can be used to surround a name
Combining these concepts leads to Regular Expressions like the following
[0-9]+("."[0-9]+)?
This matches one or digits followed (optionally, hence the final ?) by a "." and one or digits - i.e. it matches positive real numbers.
Example
 The aim of this example is to write a calculator that will
understand +, -, *, /, and ^ (power)
and give them the correct precedence, understanding brackets. Numbers can be
integers, or reals, and "scientific notation" can be used. Similar code to that shown here is on many web pages.
The aim of this example is to write a calculator that will
understand +, -, *, /, and ^ (power)
and give them the correct precedence, understanding brackets. Numbers can be
integers, or reals, and "scientific notation" can be used. Similar code to that shown here is on many web pages.
Bison
header
tokens
%%
rules
%%
user-defined functions
bison file format
We'll deal with the 2nd stage first.
Put the following into a specification file called calc.y
%{
#include <math.h>
#include <stdio.h>
#include <stdlib.h>
#define YYSTYPE double
%}
%token NUMBER
%token PLUS MINUS TIMES DIVIDE POWER
%token LEFT RIGHT
%token END
%left PLUS MINUS
%left TIMES DIVIDE
%left NEG
%right POWER
%start Input
%%
Input:
| Input Line
;
Line:
END
| Expression END { printf("Result: %f\n", $1); }
;
Expression:
NUMBER { $$=$1; }
| Expression PLUS Expression { $$=$1+$3; }
| Expression MINUS Expression { $$=$1-$3; }
| Expression TIMES Expression { $$=$1*$3; }
| Expression DIVIDE Expression { $$=$1/$3; }
| MINUS Expression %prec NEG { $$=-$2; }
| Expression POWER Expression { $$=pow($1,$3); }
| LEFT Expression RIGHT { $$=$2; }
;
%%
int yyerror(char *s) {
printf("%s\n", s);
}
int main() {
if (yyparse())
fprintf(stderr, "Successful parsing.\n");
else
fprintf(stderr, "error found.\n");
}
- There's a header section (between %{ and %}) that bison doesn't process - it goes straight into the generated file. YYSTYPE (the type used for the processed operands) is defined here.
- There's a section (going up to the first %% line) where some tokens are defined and operator precedence is set up. Order matters. The left/right distinction determines whether the operators are left- or right-associative. The %prec phrase makes a unary minus operator have a higher precedence than a binary minus. The %start line tells the parser that it is attempting initially to parse something called an Input
- There's a Rules section (going up to the second %% line) where allowable forms of expressions are listed along
with some code to show what the expressions "mean". Don't worry about the
details,
but note that
- Input is defined as empty or as a valid Input with a Line added.
- Line is either an empty line or an expression.
- the way of reducing an expression down to a number isn't too mysterious.
- 2 routines are written that are going to be added verbatim to the generated file. They're both simpler than a useful program should have. When main calls yyparse() (which will be created by bison) it will call yylex() (which will be created by flex) to get the next token.
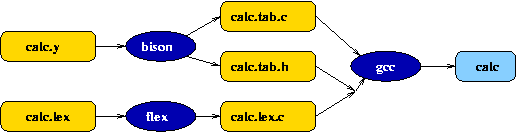
When the specification file is processed using
bison -d calc.y
it produces calc.tab.h and calc.tab.c. The '-d' makes bison produce the header file - flex needs the information (a shared list of tokens) in this.
Flex
header
regular expressions
%%
rules
%%
user-defined functions
flex file format
flex is what reads the input and processes it ready for bison
to use. flex and bison need to agree on some token
definitions - these are generated for lex in calc.tab.h.
Below is the definition file for flex. Put the code into a file called calc.lex
%{
#define YYSTYPE double
#include "calc.tab.h"
#include <stdlib.h>
%}
white [ \t]+
digit [0-9]
integer {digit}+
exponent [eE][+-]?{integer}
real {integer}("."{integer})?{exponent}?
%%
{white} { }
{real} { yylval=atof(yytext);
return NUMBER;
}
"+" return PLUS;
"-" return MINUS;
"*" return TIMES;
"/" return DIVIDE;
"^" return POWER;
"(" return LEFT;
")" return RIGHT;
"\n" return END;
- There's a section (between %{ and %}) that bison doesn't process - it goes straight into the generated file
- Up to the first %% line some regular expressions describe the types of things in the file - what "white space" is, etc.
- Then there's a section describing what should be output when each of these types of things is encountered. The action associated with white space doesn't have a return statement so control doesn't return to the parser - the next token is sought and white space is thus ignored. Strings representing numbers are evaluated by atof(). Operators are returned as tokens. \n is a newline character.
Do
flex -o calc.lex.c calc.lex
to produce calc.lex.c. At the end of this you should have the C source code for a simple calculator. The code isn't easy to read - it's not meant to be. To compile it do
gcc -o calc calc.lex.c calc.tab.c -lfl -lm
Then type
./calc
and type in mathematical expressions. E.g. typing 4e2+(2^0.5*3/2) should give you 402.121320. Then try typing in 7+8) and see if you get a useful error message. Press Ctrl and C to quit.
Makefile
Makefiles are often used in Unix to save time when compiling source code, and they're useful here, because producing a final calculator program requires quite a few stages. If you put the following into a file called Makefile
calc: calc.y calc.lex bison -d calc.y flex -o calc.lex.c calc.lex gcc -o calc calc.lex.c calc.tab.c -lfl -lm
(the indented lined must use tabs - spaces aren't good enough) then typing make will save you time whenever you want a new version of the program.
Exercises
There are many ways to extend the example
- Make it accept hex (base 16) numbers. Choose a notation that makes things easy for you - in some languages hex numbers begin with 0x.
- Make it understand the mod (%) operator - a%b where a and b are integers gives you the remainder when a is divided by b.
- At the end of input the scanner calls the user's yywrap() if it exists. If this returns 1 processing will end. Add a yywrap() function to make this so.
- The scanner has variables that users can access; for example yytext gives the current string being processed. You can use this to make the error handling more informative. Here's a start
extern char* yytext; int yyerror(char *s) { printf("%s - %s\n", s, yytext); } - When you parse long files it's useful to have a line number in the
error message. If you change the yyerror code to
extern char* yytext; extern int yylineno; int yyerror(char *s) { printf("%s on line %d - %s\n", s, yylineno, yytext); }and put%option yylineno
in calc.lex (in the section where white etc are defined) you should see the line numbers. - Get the program to read from a file rather than the command line. You can do this with
./calc < filename
if you have a text file called filename with a few lines of arithmetic expressions in it, but neater would be the ability to do./calc filename
yylex() reads input from yyin so if you set this usingextern FILE* yyin; yyin = fopen("filename", "r");in main, it should work, but you can make it friendlier and more flexible.
See Also
flex and bison are the successors of lex and yacc, with which they're mostly back-compatible. They're available on Unix/Linux machines, often being installed by default. On Macs they're bundled in with Xcode. flex++ and bison++ exist for C++ users - though they can use flex and bison as above. There are C++ options in flex and bison but I've had trouble getting them to work.
- Flex manual
- Error recovery
- The Lex & Yacc Page
- Lex & Yacc (O'Reilly Books). Their Flex & Bison book is due out in August 2009.