Shell Scripts
 This talk offers a quick introduction to "shell scripts".
This talk offers a quick introduction to "shell scripts".
Interpreted computing languages (languages that don't need to be compiled) are increasingly popular. Examples include Python (used by Google!), Perl, PHP, JavasScript and Ruby. Development times can be short, and it's easier to implement concepts - you don't lose mental focus by having to compile, etc. The resulting programs might not be as fast as those written in C++, but often that doesn't matter.
Some of these languages (PHP for example) are used on web pages. "The shell" is the program that reads what you type on the Unix command line. As well as dealing with line-editing and wild-card characters it also has a language. Shell Scripts are text files containing commands that the shell can run. If you've used the Unix command line and you've written programs in some language already, you might not find Shell Scripts too hard. Several shells exist - the Korn shell, the Bourne shell (called sh), the C shell, etc. I'm using bash, the "Bourne-Again SHell". To use any shell you'll need to familiarize yourself with
- some common Unix commands (like ls, etc), and be aware that they can take various options.
- a few shell constructions (like for, if, etc)
- using shell variables, and some facilities that are especially useful when writing scripts (like command substitution, piping, etc)
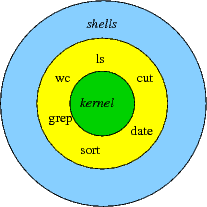
Some Unix commands that you might not use much from the command line (like cut, wc etc) are especially useful in shell scripts. Once you start combining these ideas you can soon create useful programs. So today I'll look at some commonly used commands then show how to combine them to create little utilities.
Firstly then, here are some quick examples using the ls, head, find and sort commands. Use the man command to find out more - note however that these manual pages aren't always easy to read
- ls -t | head -5 (list the 5 newest files in the folder)
- ls -l | sort -g -r -k5 | head (list the 10 biggest files in the folder)
- find . -maxdepth 3 -atime +2 -type d (list the folders - not regular files - that are 3 levels or less below the current folder and were changed more than 2 days ago)
Basic Ideas
The main material is in the Shell Scripts and Awk handout. Here are some examples that use the basic ideas mentioned above.
- Redirection - to put the output of a program into a file you
can do something like
date > outputfileTo append to an existing file use >> instead of >
- Using variables - to set and display variables you do this
i=6 echo $iTyping printenv will show the variables that the shell uses.
- Arithmetic - if you do
a=2 b=3 c=$a+$b echo $cyou'll get2+3The trick is to use let (or put the expression within (( ... )) brackets).a=2 b=3 let c=$a+$b echo $cwill give5
- Piping - the output of a program can be inputted to a program
rather than be displayed on screen. Suppose you wanted to know how many files were in the current folder. You could type ls and count the files, but wc will do the counting for you (wc stands for WordCount, but it counts lines and characters too. We'll make it output just the number of lines)
ls | wc -lwill print the answer.
- Command Substitution - the output of a command can be stored
in a variable. If you want to save the previous example's answer into a
variable you could do
numberOfFiles=$(ls | wc -l)
- Scripts - suppose you wanted to find out how many people called
Smith were on your system. You could do grep Smith /etc/passwd and
count the lines of output. Suppose you wanted to write a program called howmany so that typing ./howmany Smith would print out something like "Number of users called Smith=17" how would you do it? Create a file called howmany and in it type
grep $1 /etc/passwd | wc -lSave the file, and make it executable by doing chmod a+x howmany. When you type ./howmany Smith, the $1 in the script will have the value of the 1st parameter given to the script (namely "Smith"), so a number should be typed out showing how many lines in the password file contain the word "Smith". The output can be made more readable by changing the file contents tonum=$(grep $1 /etc/passwd | wc -l) echo "Number of users called $1=$num"As a final development we'll change the script so that it can accept more than one name. We'll use a for loop. Here's the codefor name in $* do num=$(grep $name /etc/passwd | wc -l) echo "Number of users called $name=$num" done$* expands to $1 $2 etc. The first time round the loop, name has the value of $1 (the first argument). The second time round the loop, name has the value of $2, etc, so ./howmany Smith Brown should work ok, though to finish the job we'd need to cope with the possibility of there being no users with those names.
Processes
A process is a program - not the lifeless bytes on a DVD but the active, running program. In this section I'll briefly illustrate some features of process creation.
Foreground/Background processes and job control
sleep is a program that does nothing, but it's useful when giving demonstrations. If you do
you won't get a command-line prompt back for 1000 seconds - the process is run "in the foreground". But often you want several programs running at at once. Type
and you'll get a command-line prompt back straight away, along with 2 numbers - something like
The number in square brackets tell you which "background process" you've just started (in this case it's the 1st one). The other number is the process ID (each process on the system has a unique identity number). You can manipulate processes. If you do
you'll move background process 1 (the sleep process) into the foreground. If you then type Ctrl-Z (i.e. hold the Control key down and hit Z) you'll suspend the process. You can push it into the background using
and kill it while it's in the background using
To kill the foreground process you just do Ctrl-C. You can run many background processes simultaneously.
Environments
Each process has many properties associated with it - an owner, a list of files that it's opened, the current folder, etc. When you start a new process (by typing xclock for example, or running a shell script) it will inherit many properties from its parent, but it's important to remember that the new process is mostly independent of the old. For example, if you write a script called GoToRoot containing the following code
(/ means "the 'root' folder in the tree of files") then run it from your home directory, you'll find that afterwards you won't be in the root (top) directory, you'll still be in your home directory. GoToRoot was run in a new process. To see that more clearly, you can change the file so that the process IDs are printed out -
type echo $$ to find the ID of the current shell, then run the script again. The new process moves to the root directory, but the process dies, leaving the parent process (the original command line shell) untouched. If however you type
the contents of the file will be run within the current process, and something different should happen.
And finally ... more worked examples
changesuffix
Write a program that changes all files with a jpeg suffix to a jpg suffix.
People often try
It doesn't work - *.jpeg is expanded to a list of filenames, so is *.jpg. The resulting command isn't useful. First you need to how to change a particular filename (foo.jpeg, say). The trick is to use the basename command.
will print foo. so if a filename like foo.jpeg is stored in a variable f we could do
All we need to do is put this in a loop
sizeof
Write a program called sizeof that given a program name, tells you the size of the program: e.g. "sizeof xclock" might display "xclock is 43344 bytes long"
- First we need to create a file called sizeof and make it executable. One way to do that is to type
touch sizeof chmod a+x sizeof
- Next we need to think about what goes into the file. Let's experiment on the command line first. We need to be able to find a program given its name. which does this. e.g.
which xclockdisplays/usr/bin/xclock
- How can we find the size of /usr/bin/xclock?
ls -l $(which xclock)displays-rwxr-xr-x 1 root root 43344 2008-11-21 03:16 /usr/bin/xclockThe 5th column is the size, and that's all we want, so we'll use cut, saying that ' ' (a space) is the separatorls -l $(which xclock) | cut -f5 -d' 'We want to store the result of this in a variable (s say). We can do that usings=$(ls -l $(which xclock) | cut -f5 -d' ')That's solved our main problem.
-
Now let's get the script working.
Inside the script, the name of the program we're looking for is $1
(because it's the first argument),
and so the location of that program is which $1. So version 1 of
our script is
s=$(ls -l $(which $1) | cut -f5 -d' ') echo $1 is $s bytes long
- That works if we type "sizeof xclock", but is messy if we just type "sizeof", forgetting to give an argument. Let's make sure that users provide exactly 1 argument by
beginning the script as follows
if [ $# -ne 1 ] then echo "$0 needs exactly 1 argument" exit fi
- We should also deal with situations where the argument isn't a program. which returns true if it finds the program and false otherwise. When we call which for this purpose we don't want it to display anything, so we'll send the output and errors to /dev/null (a black-hole for bytes). Our final program is
if [ $# -ne 1 ] then echo "$0 needs exactly 1 argument" exit fi if which $1 >/dev/null 2>/dev/null then s=$(ls -l $(which $1) | cut -f5 -d' ') echo $1 is $s bytes long else echo "$1 isn't a program" fi
Note that about half of this program deal with errors - par for the course.
storebyyear
Write a program called storebyyear that looks at all the files in the current folder, putting all those creating in 2009 in a folder called "2009", and similarly for other years. It should create the folders if they don't already exist.
Firstly then, how do we get the year of a file? If the output of ls -l is in the following format
we can use cut to pick out the "2008-11-21" field (the 6th field, where fields are separated by spaces), then cut again (getting the 1st field, where fields are separated by '-') to pick the "2008" part of this field. Then we can check to see if we need to make a new folder before copying the file. Here, without error checking is a program.
How could you adjust this so that it only deals with JPEG files?