git
Why use version control?
I think most people who write programs or documents use version control even if they do so informally, saving versions as they go along. Maybe they create program_old.cc or better still something like programApr2019.cc. Their folders might get a bit cluttered, but at least they don't have to learn a new version control system.
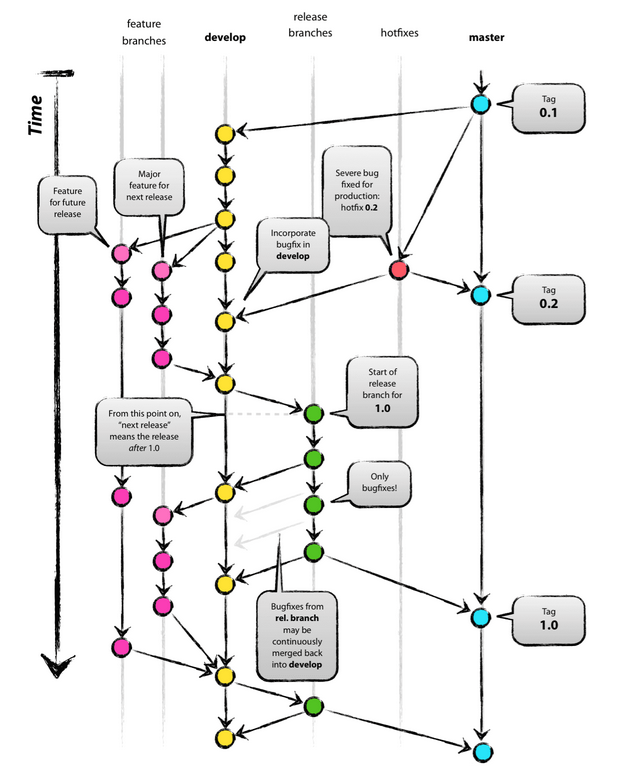 With small, linear, one-file programs this method might be ok. Things become for complicated when the program involves multiple files or collaboration. As soon as there's branching too (as in the diagram in the right) , informal version control becomes error prone - quite possibly the weak-point of the whole project.
With small, linear, one-file programs this method might be ok. Things become for complicated when the program involves multiple files or collaboration. As soon as there's branching too (as in the diagram in the right) , informal version control becomes error prone - quite possibly the weak-point of the whole project.
Why use git?
Many version control systems exist, some built into applications. Version control should be light-weight and easy to use, but powerful enough to deal with big projects. You don't want it to be completely transparent, recording every change to the files because that would be confusing. You want to be able to take copies of the files on demand.
git was invented by Linus Torvalds to cope with developing Linux. For small, linear, one-file programs it's as easy to use as informal methods. And if it can cope with the international Linux project, it can cope with anything. Microsoft are shifting Windows development onto it. It lets you backtrack if things go wrong, and in team projects it helps coordinate modifications. It's free, and can be used across the Web. Even so, because it's designed to cope with complex situations it can seem like overkill in simpler situations. Note that
gitworks with text files, so it doesn't work with Word filesgitis gradually taking over from the alternatives. According to Wikipedia, about 30% of UK permanent software development job openings have cited Git.
Why use BitBucket, GitHub or GitLab?
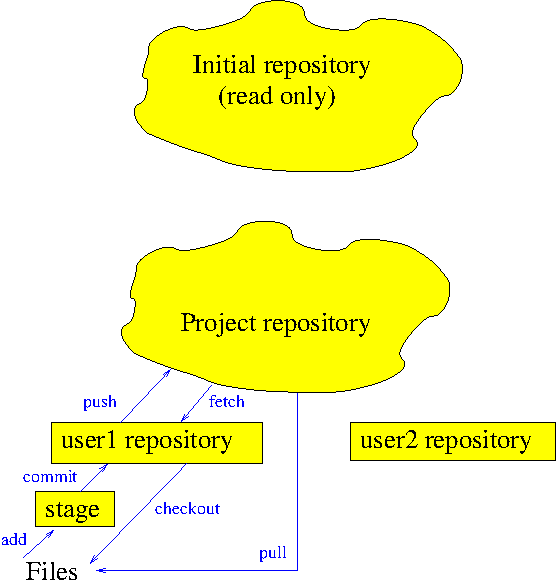 Facilities like Bitbucket, GitHub or GitLab let you store git-managed files in the cloud under password control. As well as being a useful back-up facility this is useful when there are multiple authors, and when you want to make your code/document easily available to others. Such facilities are not dealt with here. The way shared repositories work is that users "push" their material from their private git repository into the shared repository, so the early exercises here will still be useful.
Facilities like Bitbucket, GitHub or GitLab let you store git-managed files in the cloud under password control. As well as being a useful back-up facility this is useful when there are multiple authors, and when you want to make your code/document easily available to others. Such facilities are not dealt with here. The way shared repositories work is that users "push" their material from their private git repository into the shared repository, so the early exercises here will still be useful.
These notes are written primarily for Unix users working from the command line. Some sections are for local users. The notes start with the situation where 1 person is working with 1 "repository" (storage area) then consider team projects.
Resources
Numerous resources are online. You won't need to refer to them to do the worked examples on this page, but you might find them useful later. Amongst them are -
- GPRS tutorial - an 83 page PDF document with many worked examples
- gittutorial - A tutorial introduction to Git - has a useful section on "Using Git for collaboration"
- gitworkflows - An overview of recommended workflows with Git
- Version Control with Git
- Tutorials
- git-guide
- Code Academy's "Learn Git"
- a simulator
Some of these quickly become detailed. A git cheat sheet might be useful.
Terminology
The documentation mentions
- "staging" - putting files under version control.
- "repository" (or "repo") - the place where git keeps its files
- "working directory" - the place where the files that you're working on are
- HEAD - the end of the current branch of development
- master - The default development branch.
- checkout - nothing to do with checkout counters in supermarkets. It's getting a version out of the repository.
The Unix command line
 Some programs (for example, VS Code, an editor that's part of the Anaconda suite of programs) have
Some programs (for example, VS Code, an editor that's part of the Anaconda suite of programs) have git facilities built into them. However, this document assumes that you'll be using a Terminal window on a Unix/Linux/MacOS machine. You may not have used one of these before (quite a few of the problems people have with git are really command line issues), so here's a very brief guide to some commands
ls- list files in the current foldermkdir folder_name- make a new folder (unix calls folders directories)cd folder_name- go to the named folderpwd- find out which folder you're inmore file_name- display the contents of file_name on the screenecho text > file_name- put the text into the file, overwriting what was there, creating the file if necessaryecho text >> file_name- append the text to the file[up arrow]- retrieve the previous line. You can use this repeatedly, and edit the retrieved line. Wherever the cursor is, pressing the Enter key will run the whole line
git is usually pre-installed on Unix/Mac systems nowadays.
Setting Up
The git commands store the updater's name and can sometimes start editors. Running the following commands (you only need to do so once for each machine you use) will stop git warning you that you've not configured your set-up. You can do the first worked example below without any of these being correct (you won't need an editor, and all the files are temporary). On Linux you could set the editor to be emacs.
git config --global user.name "Your Name" git config --global user.email YourEmailAddress git config --global core.editor YourEditor
A worked example - one user, one repository
Here I add a line to a file each time using the echo command, but you could edit the file instead. Files are created in the "/tmp" folder, a scratch area in unix systems.
- Create an empty folder and create a repository
mkdir /tmp/gittest1 cd /tmp/gittest1 git init
- Create a file called
one, tellgitthat you want to keep track of it, then store the current version of it and give the version a name. If thecommitcommand warns about your configuration, try the Setting Up commands.echo first line > one git add one git commit -m "a one liner" git tag -a -m "base level" base
Thegit addcommand adds the named file to the list of files thatgit commitwill save. You don't have to add a tag, but as you'll see later, it makes jumping between versions easier. - Add another line to the file and save a version. Note that this time the
commitcommand has a "-a" flag, meaning that it will save all the files (i.e. we don't need use "add" to specify which files to save). Then do it again.echo second line >> one git commit -a -m "a two liner" echo third line >> one git commit -a -m "a three liner"
If you type more one you'll see that your "one" file will now contain
first line second line third line
Now you can view the structure of the current project using
git log --graph --oneline --decorate --all
which displays something like this (your numbers will be different)
* 0ad5dd6 (HEAD, master) a three liner * 265211c a two liner * 66b374a (tag: base) a one liner
Each of these lines denotes a stage that you can go back to. To return to the start, type
git checkout base
(don't worry about the long note that git displays) or use the numerical name - in this case 66b374a
git checkout 66b374a
If you look at the "one" file now using more one, you'll see your original version
first line
If you type
git checkout master more one
you'll see your newest version again. For a small, single user project, this may be all you need to know about git. If you type
git commit -m "a comment"
every so often during your project you'll build up a sequence of back-up versions of your work without cluttering your folder. At any time you can do
git log- to get a list of dates when you committed things, and what you committed.git diff ...- to compare versions. For example,git diff base master
will show the differences between your first and final versions (in a format that you'll soon get used to).
Your folder won't be cluttered - everything's in the .git folder. If you set up a remote repository and do git push after each commit, you'll have a remote backup of your work. Better safe than sorry.
Branches
This project has developed linearly so far. Let's suppose you're already having second thoughts about how you project's developing. Typing
git checkout base git checkout -b bough
goes back to the start and gets ready to produce a branch called "bough". Doing
echo a new idea >> one git add one git commit -m "along the branch" git log --graph --oneline --decorate --all
produces something like
* 3246626 (HEAD, bough) along the branch | * 0ad5dd6 (master) a three liner | * 265211c a two liner |/ * 66b374a (tag: base) a one liner
showing that now there are 2 tracks of development from base- the current one (shown as a vertical line leading to "bough") and the one we first produced (the "master").
To create a new branch named "experimental1" without checking it out, use
$ git branch experimental1
If you now run
git branch
you’ll get a list of all existing branches:
* bough experimental1 master
The "experimental1" branch is the one you have just created, and the "master" branch is a default branch that was created for you automatically. The asterisk marks the branch you are currently on. Type
git checkout experimental1
to switch to the experimental1 branch. We'll add text to the file, and commit the change:
echo an experiment >> one git commit -a -m "my first experiment"
Add another branch now, and switch back to the master branch
git checkout bough git branch experimental2 git checkout experimental2 echo another experiment >> one git commit -a -m "my second experiment" git checkout master
If you look at the "one" file now (e.g. by typing more one) you'll see the three line version - because you’re back on the master branch. You can make a further change on the master branch. Let's add something
echo fourth line >> one git commit -a -m "a four liner"
By now the branches have diverged, with different changes made in each. Typing
git log --graph --oneline --decorate --all
will produce something like this -
* 7ad13d3 (HEAD, master) a four liner * 97f7ec4 a three liner * 999886f a two liner | * ad63635 (experimental2) my second experiment | | * 7e4e446 (experimental1) my first experiment | |/ | * a60312d (bough) along the branch |/ * f5b2477 (tag: base) a one liner
Already you have 3 streams of development on the go, and different versions of each. This is typical when writing a program (or a poem come to that). Suppose now that you thought experimental1 was a good idea. To try merging the changes into the master sequence, run
git merge experimental1
If the changes don’t conflict, the merge will be done automatically. If, as here, the two strands of development conflict, you'll get a message something like
Automatic merge failed; fix conflicts and then commit the result.
Markers will be left in the problematic files showing the conflict. If you do more one you'll see that it's been changed -
first line <<<<<<< HEAD second line third line fourth line ======= a new idea an experiment >>>>>>> experimental1
This shows you that the 2 versions have a line in common but then differ - above the "=======" line is the master version, and below is the experimental1 version. Typing
git diff
will also show the differences. You will need to edit the one file to merge the 2 version manually. You could for example make the contents of one be
first line second line third line a new idea an experiment
You can then type
git commit -a -m "merged version"
to commit the result of the merge. At this point you could delete the experimental branch with
$ git branch -d experimental1
Typing
git log --graph --oneline --decorate --all
now displays something like
* 6f804c4 (HEAD, master) merged version |\ | * f7da77f my first experiment * | b52fa9c a four liner * | 0ad5dd6 a three liner * | 265211c a two liner | | * d8931e0 (experimental2) my second experiment | |/ | * 3246626 (bough) along the branch |/ * 66b374a (tag: base) a one liner
 showing the merge and the abandoned
showing the merge and the abandoned experimental2 branch. If you type
git diff master experimental2
You'll get
diff --git a/one b/one index ffea0ad..1436297 100644 --- a/one +++ b/one @@ -1,5 +1,3 @@ first line -second line -third line a new idea -an experiment +another experiment
showing which lines the 2 versions have in common ("first line" and "a new idea") and which lines are in one version but not the other (denoted by the - and + symbols). Some versions of git show the differences in a friendlier way, colour coding the changes. Also they show the versions and branches in a friendlier way (see right, from bitbucket).
detached HEAD
 Normally the HEAD variable stores the name of a branch-end. However, git also allows you to check out an arbitrary commit that isn’t necessarily the tip of any particular branch. In this case HEAD is said to be "detached". If you continue the above example by doing
Normally the HEAD variable stores the name of a branch-end. However, git also allows you to check out an arbitrary commit that isn’t necessarily the tip of any particular branch. In this case HEAD is said to be "detached". If you continue the above example by doing
git checkout base
you'll be told "You are in 'detached HEAD' state". It's important to know that you're in that state because if you make changes to files and commit them, they'll disappear the next time you do a checkout, so beware.
Names
Descriptive text ("tags")can be added to nodes. There are 2 types of tags. Annotated tags are meant for release while lightweight tags are meant for private or temporary object labels. For this reason, some git commands for naming objects (like git describe) will ignore lightweight tags by default.
Having more than one repository
If you want further backups, or if you're part of a team, you'll be using more than one repository. A common way of working is to
- Create a private repository
- Clone it to create another repository (maybe on a distant machine)
- Change your files
- Use
addto define which files you want backed up to your private repository - use
committo back them up to your private repository - use
git pushto update the remote repository
I'll refer to the non-private repository (which by default will be called origin by git) as the "remote" one. Now for some details of the extra commands you'll need -
pull- update the private repository from the remote one, and update the code.push- update the remote repository. If the remote repository isn't a direct ancestor of the private directory (which can happen if another person has changed the remote repository since your last "pull"), the push will fail. Note that "git push ..." doesn't transfer the tags.fetch- update the private repository from the remote code, but don't update the code.
Worked example for CUED users - 2 users, 3 repositories
If you follow these commands, you can simulate a situation where a user user1 has created a private repository, and cloned it into a folder called remote so that it can be shared. Then user2 clones this shared repository.
cd /tmp rm -rf user1 user2 remote mkdir user1 user2 remote cd user1 mkdir Software cd Software hostname > names git init git add names git commit -a -m "add names" cd /tmp/remote git clone --bare /tmp/user1/Software cd /tmp/user2 git clone /tmp/remote/Software.git
(the --bare option is needed for the shared repository). Currently you're in user2's area. After
cd Software more names |
You'll see that user2 begins with a copy of the names the file that user1 created. The following commands simulate a situation where user2 makes a change to that file and commits it to their own repository. They then push the changes to the shared repository
echo "//an extra comment" >> names git commit -a -m "names change" git push |
Now we'll pretend to be user1
cd /tmp/user1/Software |
If you look at the names file you'll see that it hasn't changed. Suppose user1 wants to update their private version of the project. Doing
git remote add origin /tmp/remote/Software.git git pull origin master |
will update the private repository from the shared repository, and update the source code files too. names will have changed, and everyone's in sync again. Now do
echo "//an extra user1 comment" >> names git commit -a -m "names change by user1" git push |
to emulate user1 making a change and updating the shared repository. The 2 programmers are out of sync again. Do
cd /tmp/user2/Software echo "//an extra user2 comment" >> names git commit -a -m "names change by user2" |
to emulate user2 making a different change to the same file. Now if user2 tries to update the shared repository by doing
git push |
git says (amongst other comments)
Merge the remote changes before pushing again. |
and if they attempt to merge the latest version of the shared repository with their own code by doing
git pull |
git says
CONFLICT (content): Merge conflict in names Automatic merge failed; fix conflicts and then commit the result. |
The problem is that user2's code in their private repository is out of sync with the code in the shared repository, but git doesn't know how to merge the 2 versions. user2 needs to look at the change that user1 pushed to the remote repository, manually merge them into their own changes, then push. Typing
git diff |
will display the differences. To resolve them, you could do
echo "//an extra user1 comment" >> names git commit -a -m "names change by user2" git push |
and everything is back in sync. This may seem like a lot of work, but if team members mostly work on different files, it's painless enough. Besides, the problems that git automatically detects are problems that you need to deal with anyway. Note that you can find out where your remote repository is by doing
git remote -v
which in this case produces
origin /tmp/remote/Software.git (fetch) origin /tmp/remote/Software.git (push)
Notes for CUED GF2 students
The following lines create a repository that team members can share.
cd cd GF2_shared/Common/ git clone --bare ~ahg13/ugrad/SoftEngProj
In the git documents, this shared repository is often called the "remote" repository (because in general it's on a remote machine). Each member then does
cd cd GF2_shared/myuserid/ git clone ../Common/SoftEngProj.git
to create a private development area. The code is in the SoftEngProj folder, with all the git-related material in the ".git" folder. A ".gitignore" file already exists. It specifies which files "commit -a" should ignore.
Your remote repository will by default be known to git as "origin"
More matters arising
- The
loghas many options that are particularly useful in a large project. For example,-
git log --pretty="%h - %s" --author=tpl --since="2014-10-01" --before="2014-11-01" --no-merges -- t/- display usertpl's contributions between the 2 dates shown. git log HEAD..FETCH_HEAD- show everything that is reachable from the FETCH_HEAD but exclude anything that is reachable from HEADgit log HEAD...FETCH_HEAD- show everything that is reachable from either HEAD or FETCH_HEAD, but exclude anything that is reachable from both of them
-
git request-pull- Generates a summary of pending changes for the team. Imagine that you built your work on your master branch on top of the v1.0 release, and want it to be integrated to the project. First you push that change to the remote repository for others to see:git push https://git.ko.xz/project master
Then, you run this command:git request-pull v1.0 https://git.ko.xz/project master
which will produce a request to the upstream, summarizing the changes between the v1.0 release and your master, to pull it from the remote repository.-
git statuswill tell you about currently tracked files, etc.
See Also
- Trouble-shooting
- A book (500+ pages)
- © Cambridge University, Engineering Department, Trumpington Street, Cambridge CB2 1PZ, UK (map)
Tel: +44 1223 332600, Fax: +44 1223 332662
Privacy policy
Contact: helpdesk