git: Trouble-shooting
 This document brings
together some common issues that new users of
This document brings
together some common issues that new users of git encounter.
The basics
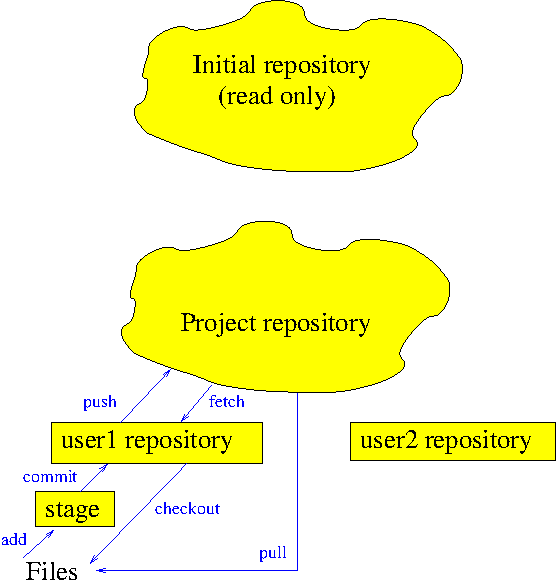 Not all students have a clear mental map of how
Not all students have a clear mental map of how git works. One common approach
(used by our first years) is that
one team member creates a copy (‘fork’) of the provided repository to produce
the project repository (or "repo"). The code in this repository can
be made sharable and then cloned by each user (if they're using something like bitbucket then they can click on "clone" to get a command line that they can copy/paste onto the command line of their own machine and run to get a local copy).
From then on, a common work cycle is for a user to pull the latest version from the project repository (because colleagues might have added new code), then change their code, add the files and commit the changes into their own repository then push updates to the Project repository.
Note that the initial repository is just used to get the initial source from. It shouldn't be involved with subsequent pushes and pulls (but students make that mistake).
Dealing with clashes
Sooner or later, students will make changes that clash with those of their colleagues. They should
- do "git pull" to download the latest version of the project repository. If git still tells them that they need to merge, they might try "git diff" which should show them differences between the current state of the file and the most recently saved version.
- If they've made few changes locally, and they just want to get rid of them, they can do "git checkout the_filename" on each file that they want to revert so that their disc version matches the version in their private repository.
- If they want to merge the changes, they need to use "git merge" then look for lines like
<<< HEAD ... ======= ... >>> master
or similar. This shows the regions where there are differences. When they've edited to resolve the differences, they can do "git commit" and then "git push" to update the project repository.
Things that can go wrong
git tries to report what the problem is, and sometimes suggests solutions, but the messages aren't always easy to understand. If you put the message into a search engine, you'll often get clearer explanations. Here are some common problems that aren't purely git-related -
- The working directory - Students aren't used to using the command line, and may not have the idea of a working (current) directory, but they need to know which directory they're in so that they can run git correctly. Some useful commands are
Sometimes, without meaning to, users run git from a subfolder. It fails, so they run git init or clone, after which git works again for a while, but things will get confusing later. Removing the .git folder from the subdirectory might eventually be needed to tidy things up.Operating system print working directory move to new directory list files Unix/Mac pwd cd directory-name ls -l Windows cd cd directory-name dir - Cache files - for efficiency reasons, Python creates a
__pycache__folder and*.pycfiles. These should be ignored bygit. If a file called.gitignoreexists containing__pycache__/ *.py[cod] cache/
then the files will be ignored. Such a file should exist for local students if they clone correctly. - Too many repositories - If they use "git clone" they needn't use "git init". Cloning automatically creates a remote connection called origin pointing back to the original repository. If the students' remote repository
isn't behaving as expected, they may somehow be using the wrong one (they may have created extra repositories). Get them
to type "git remote -v". Typical output is
$ git remote -v origin https://bitbucket_username@bitbucket.org/repo_owner/floodsystem.git (fetch) origin https://bitbucket_username@bitbucket.org/repo_owner/floodsystem.git (push)
where 'bitbucket_username' is self-explanatory and 'repo_owner' is the creator of the original repository. They can set their remote repository usinggit remote set-url origin the-true-url
- Too many files in repository - git tries hard to record all changes. The downside of this is that if you make an admin mistake which you want to correct, it's likely that the mistake and corrections will be logged too. One example is if you do
git commit -awhen you have many junk files around (emacs back-up files for example). github help offers one solution. Removing multiple files is far more tedious than adding them, so beware. - Group file permissions - by default git honours the file permissions on the file it's checking in so, if this doesn't have group write permission, neither will the file in the repository. This behaviour can be fixed by adding "--shared=group" when setting up the shared repository using "git init ..." or subsequently by running "git config core.sharedRepository true" in the shared repository directory (i.e. Common). The latter will only affect files subsequently added so you'd need to add group write permission to any files without it in the objects directory's subdirectories using "chmod g+w filename" or just to do the lot with "chmod -R g+w objects/" (info from jmrm1).
- If they get a "You are in ‘detached HEAD’ state" message they need to be careful because if they make changes to files and commit them, they'll disappear the next time they do a checkout. Perhaps they should do "git checkout master".
- vi - if they on a unix machine and they use "git commit" without adding a comment, by default an editor called vi will run.
They can type
[Esc] :q! [Return]to exit that editor. - remote: HTTP Basic: Access denied - Sometimes when cloning or pushing, users aren't prompted for a password. Instead they're denied access. Stackoverflow offers many possible solutions. Possible complications are that
- They may have chosen to authenticate using Google, etc
- They may have a .ssh folder
- They may be using the wrong gitlab location
The most common cause of the problem seems to be that the windows/mac password manager doesn't update when the user changes their gitlab password
If on Windows
git config --global credential.helper
returns
wincred
try
git config --global credential.helper cache
I don't know if the same fix works on Macs. They use keychain.
Removing .gitconfig is a more drastic way of dealing with this. Or, on Windows, they can try
Control Panel -> Credential Manager -> General Credentials
and updating the gitlab password manually
Useful diagnostic and miscellaneous commands
- git remote -v - list the remote repositories
- git status - shows changes have been staged, which haven’t, and which files aren’t being tracked by Git.
- git config --list - list the config settings
- git log --graph --oneline --decorate --all - show the log using ASCII art
- git diff HEAD~1
filename- shows the differences made to the file since the last commit. - git reset --hard HEAD@{1} - undo "git pull".
Tutorials
Many tutorials exist. https://www.atlassian.com/git/tutorials provides a useful list. Other places include